Escalation Matrix Design for High-Volume Intake: Who Gets Notified, When, and How (Without Ticket Chaos)
By Matt O'HaverLast modified: June 2, 2026
Voted Top Call Center for 2024 by Forbes
Virtual Receptionists
Save time and money with our virtual receptionists.
AI Receptionist
AI-powered receptionist that answers, routes, and qualifies calls 24/7.
Enterprise Solutions
Solutions designed to scale with your organization’s needs.
Legal Services
Our virtual legal receptionists are experts in legal intake.
Last modified: June 2, 2026
High-volume intake breaks down in predictable ways: urgent issues get buried, the wrong people get pinged, and your team starts creating “shadow processes” in chat threads and sticky notes. The fix is not “more tickets.” The fix is a clear escalation matrix that turns urgency into repeatable routing, notification, and handoff behaviors.
This guide is for enterprise and multi-location service businesses, legal intake-heavy firms, and healthcare practices that run overflow, after-hours, or 24/7 inbound coverage. You will learn how to build a call center escalation matrix and intake escalation workflow that sets incident severity levels, defines warm transfer procedures, and enforces escalation SLAs without creating a service desk mess.
If you are past the “basic phone tree” phase and need an operational, auditable escalation policy for contact centers, this article is designed to be copy-pasted into your internal SOP format.
An escalation matrix is a single, shared decision system that answers three questions for every meaningful intake event: who gets notified, when they get notified, and how the notification happens. It is not a list of “important people” or an org chart. It is the operational rulebook that prevents urgent call handling SOPs from becoming tribal knowledge.
In high-volume environments, escalation failures usually come from ambiguity. Two agents interpret the same situation differently, create different urgency, and take different actions. A matrix removes interpretation where you want consistency, while still leaving room for human judgment in the gray areas.
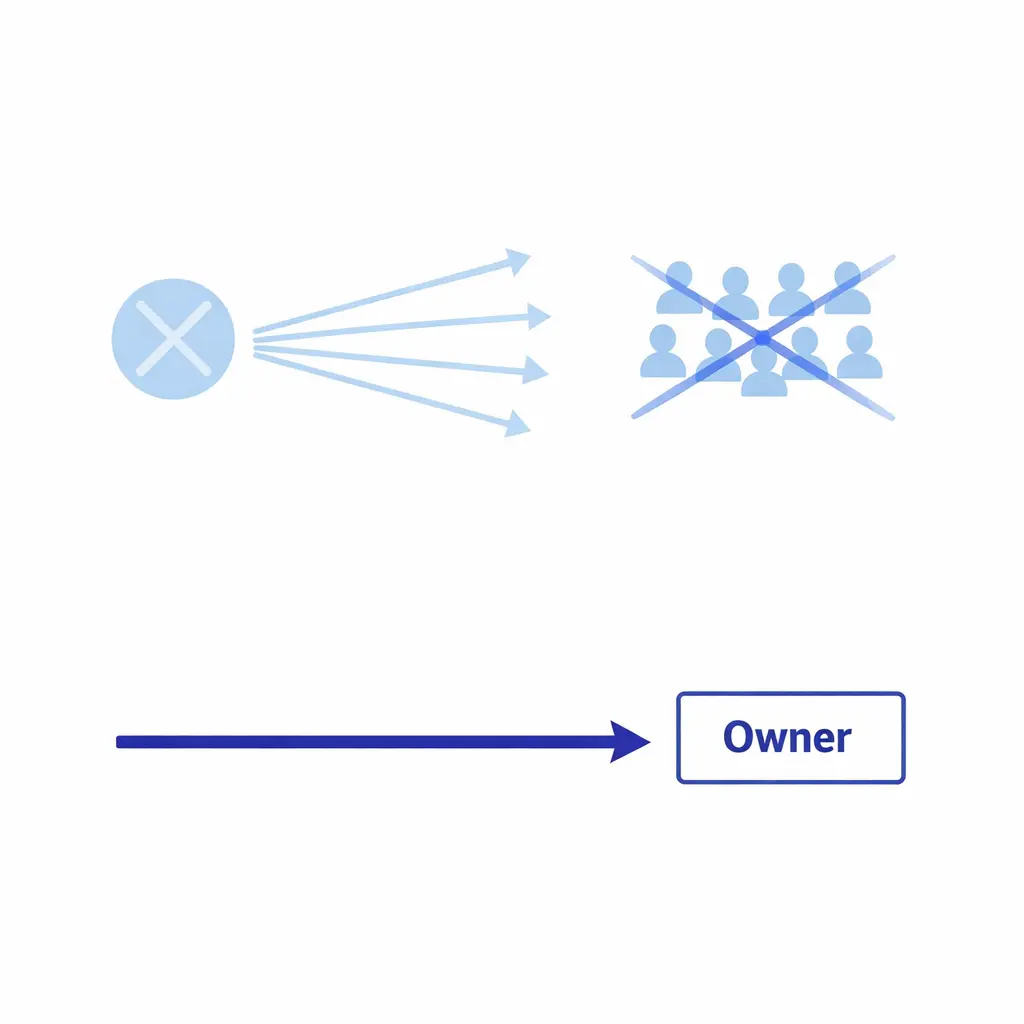
“If it’s important, notify everyone” is the matrix anti-pattern. Broadcast fanouts diffuse responsibility and create notification fatigue — the opposite of what an escalation matrix is supposed to deliver.
Intake is no longer just “calls answered by the front desk.” Most teams now operate across multiple locations, time zones, and coverage models, including overflow and after-hours answering. That pushes escalation design from “nice to have” into “core operations,” because the escalations are the glue between the answering layer and the business owners who must act.
At the same time, more workflows are hybrid: part phone, part SMS, part email, part service desk. If you do not define your service desk escalation rules and warm transfer procedures explicitly, the system naturally drifts into ticket chaos: duplicate threads, conflicting instructions, and missed acknowledgments.
Overflow and after-hours intake should feed the same on-call roles using the same severity and channel rules — not a side process. If your matrix only covers business hours, you have not built a matrix; you have built a daytime SOP.
You do not need a 40-page manual to get value. You need a minimum viable escalation matrix that is short, testable, and enforceable. Start with these components, then expand only when you can measure improvement.
If your matrix cannot be executed by a new agent on a night shift without extra coaching, it is too complex. Complexity is not sophistication; it is usually unowned risk.
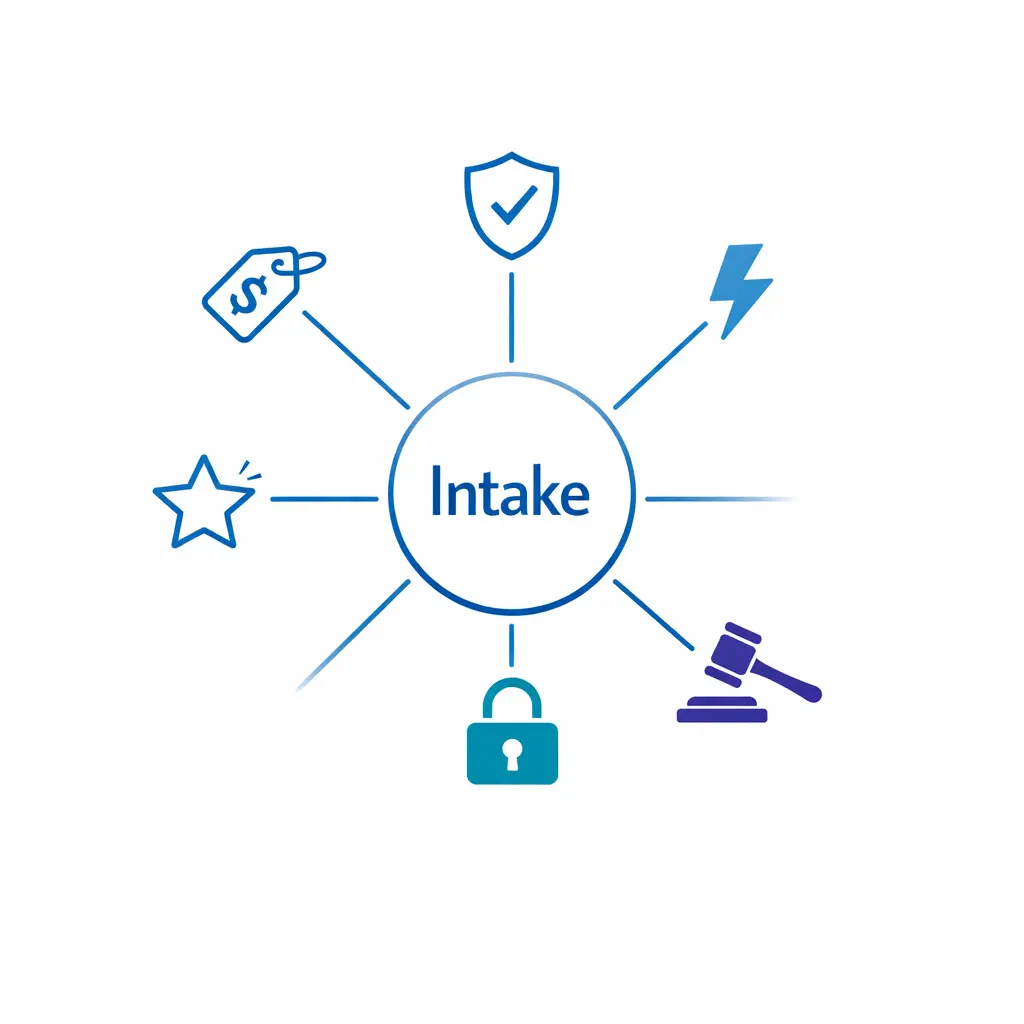
Most teams jump straight into incident priority levels without first defining what an intake event is in their world. Start by listing the events that matter operationally. You are building a practical map of what can happen, not an abstract taxonomy.
Keep the list short. If everything is an “event,” nothing is, and you will recreate noise through escalation. Use the categories above as a starter and prune anything that does not require different routing in your operation.
A dispatch failure is a useful canonical example: a missed appointment routes to on-call dispatch with a defined backup step if the primary does not acknowledge. Same shape works for safety, security, and revenue-critical events.
Severity should be defined by required action and time sensitivity, not by how upset the caller is. A clean severity model reduces subjective debates and makes on-call escalation process coverage far easier to staff. A practical four-level model is enough for most call center escalation matrix designs.
Action is required now; delaying creates immediate safety risk, irreversible loss, or mandatory emergency response. Notification: live warm transfer to the designated responder plus backup paging. SLA: acknowledge in minutes; engage immediately. Handoff: capture exact words, location, callback, and any immediate instructions given.
S0 (now), S1 (within an hour), S2 (within standard windows), S3 (routine). Four cards, each with one notification rule, one acknowledgment SLA, and one handoff format — that is the entire model.
Action required within a short window (often under an hour). Notification: warm transfer if the responder is available; otherwise page/SMS and create a single ticket. SLA: acknowledge quickly; engage within a defined window. Handoff: include constraints (deadline, appointment time, court date, dispatch window).
Important, but can wait until business hours. Notification: ticket + email summary; optional next-business-day callback. SLA: acknowledge and assign within standard windows. Handoff: structured summary, caller expectations, next-step owner.
Standard requests, general questions, scheduling, non-urgent updates. Routed to standard queues; no paging; standard service targets; standard intake form fields only.
Add a VIP lane for prioritized routing without elevating to the on-call paging tree. VIP context belongs in routing logic, not in severity — otherwise you train the team to wake people up for status calls from key accounts.
If you want a cross-functional anchor for the idea that incident handling benefits from categorization and prioritization, align your definitions to the general lifecycle and triage mindset described in the NIST Computer Security Incident Handling Guide (SP 800-61 Rev. 2) without importing security-only details into customer service.
Escalation matrices fail when they are tied to specific individuals. People change roles, go on vacation, or stop answering after being burned by noise. Your matrix should notify roles with coverage, not “the one hero who always answers.”
For multi-location operations, duplicate the responder roles by region or business unit, then add one global duty manager for true cross-site incidents. This is how you prevent “everyone got pinged” situations that still result in nobody owning the next step.
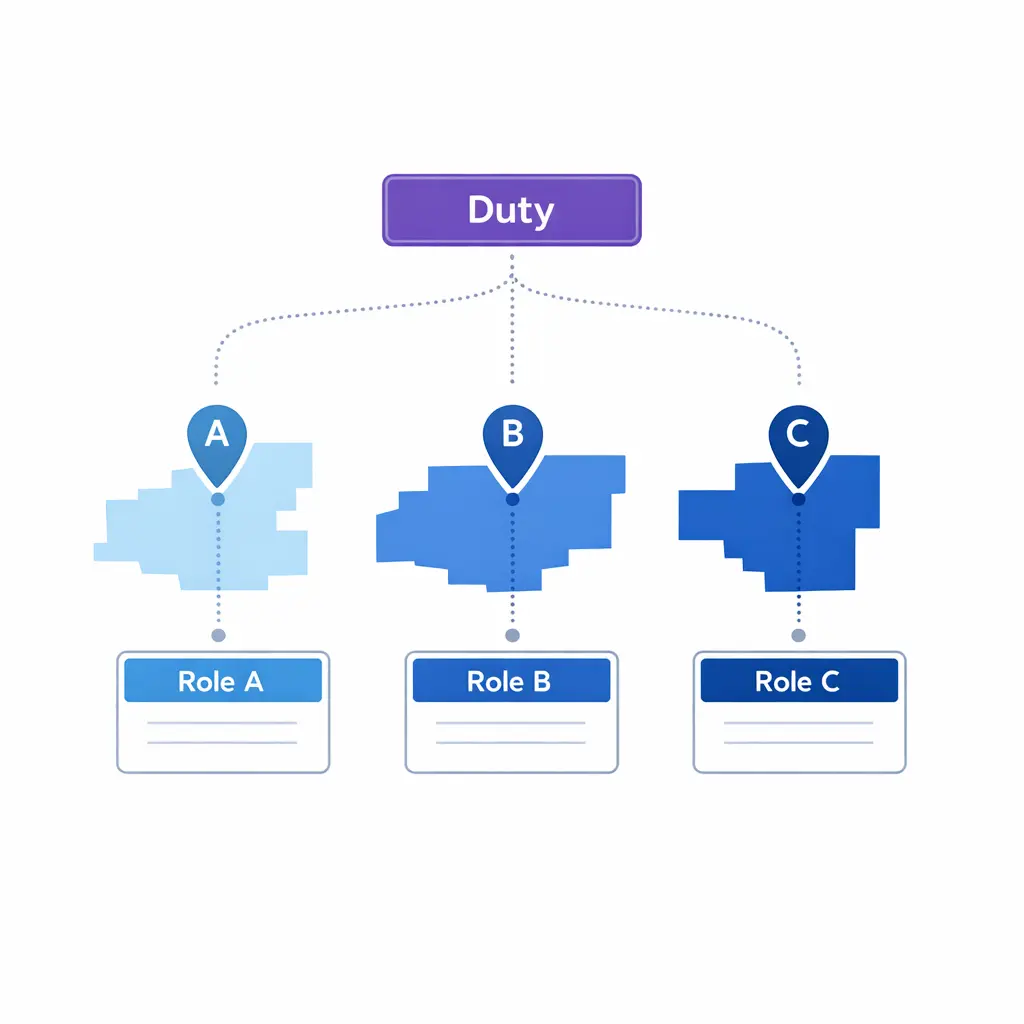
Multi-location coverage routes calls by region to the local primary and secondary responders, with a single global duty manager available for cross-site incidents — never a free-for-all distribution list.
Most escalation policies for contact centers talk about response time but ignore acknowledgment time. That is where escalations actually break. If nobody acknowledges, the agent does not know whether to keep the caller, call back, or escalate again. Write your escalation SLAs as a simple chain.
Tie escalation to the acknowledgment SLA, not the engage SLA. The moment acknowledgment fails, the system should automatically move to the next backup or duty manager — no human judgment required.
Acknowledgment is the trigger that protects every other SLA. Build your routing engine so the next responder is paged automatically when acknowledgment is missed — not when engagement is missed — because by the time engagement fails, the customer has already noticed.
Channel sprawl is the root of ticket chaos. If S1 events are sometimes in email, sometimes in chat, sometimes in a CRM note, and sometimes in a ticket, you will lose critical details and create duplicated work. Pick one primary system of record for each severity band and enforce it through tooling, not goodwill.
If you use an on-call tool, reflect its mechanics in your workflow. For example, an escalation policy with acknowledgments and automatic step-ups is a built-in pattern in tools like PagerDuty escalation policies, which is useful as a mental model even if your implementation is different.

Warm transfers are powerful because they create immediate continuity for the caller. They are also dangerous because they can trap agents in long hunts for an available human. Your warm transfer procedures should protect both the caller experience and the contact center’s capacity. Use a two-path rule: Path A is “warm transfer required” for S0 and select S1 scenarios where miscommunication is unacceptable; Path B is “warm transfer optional” for S1/S2 scenarios where a clean written handoff is sufficient.
Put a timer on every warm transfer attempt. If the responder cannot be reached within the warm-transfer timer, fall back to the backup notification method and set caller expectations — callback window, next steps, and what to do if conditions change.
Enterprises often run both an intake operation and a service desk. The failure mode is “duplicate records everywhere,” where the contact center logs something in the CRM, the service desk logs a second ticket, and the field team starts a third thread in chat. Fix this with two rules.
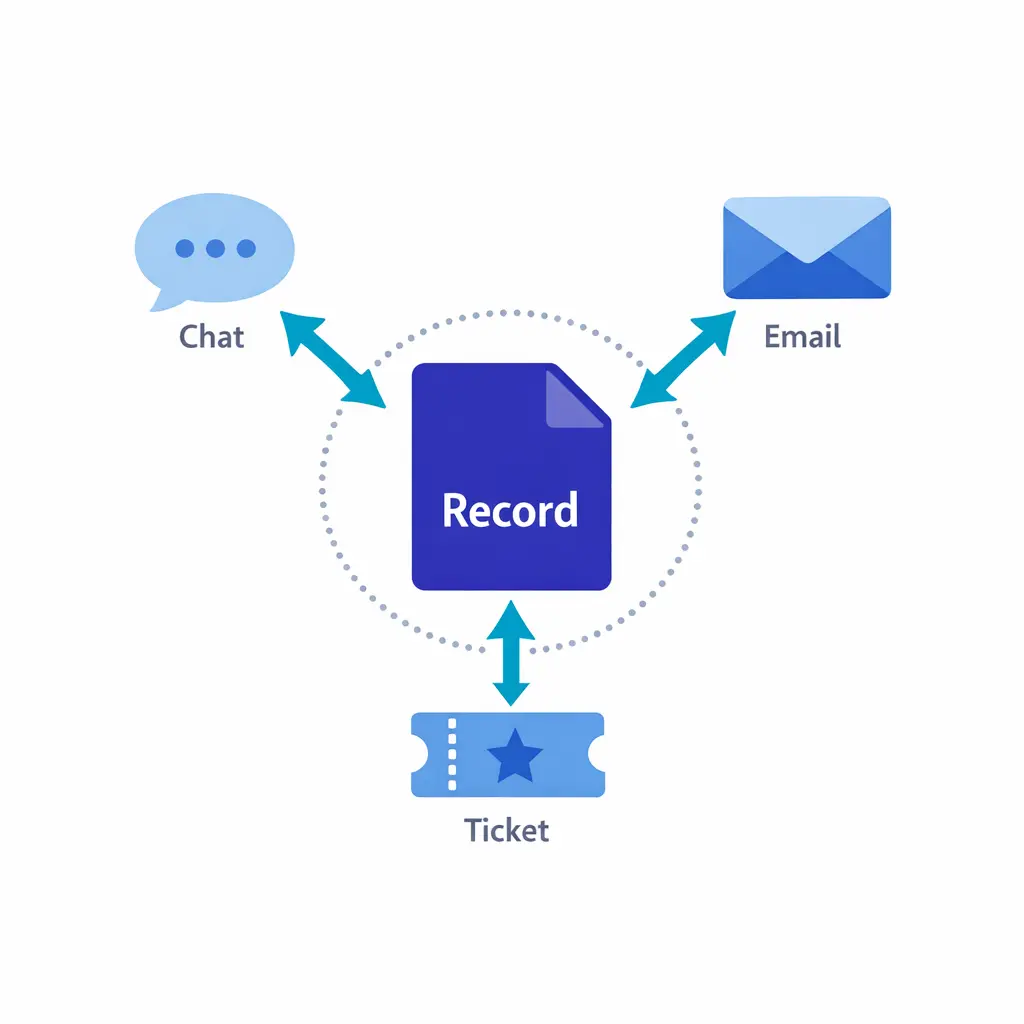
Multiple channels point to one canonical incident record. Phone call, service desk ticket, and field team thread all reference the same ID — no parallel records, no “whose ticket wins.”
If your service desk is the system of record for operational incidents, then your contact center’s job is to create the ticket correctly once, attach the structured handoff, and notify the right on-call role. If your CRM is the system of record for client matters, then the service desk work must attach back to the CRM matter ID.
Escalation is not just operational. It can be a compliance and trust boundary, especially in healthcare and legal intake escalation workflows. The matrix should explicitly define what information can be shared in which channels and what must stay inside approved systems.
Build the matrix “minimum necessary” by design: SMS or pager messages carry only what triggers the response, while details live in secured systems. The notification triggers action; the record holds the facts.
For healthcare practices and clinics, escalation messages often contain protected health information. Build your workflows so that SMS or email notifications carry only what is needed to trigger the response, consistent with the HIPAA Privacy Rule’s minimum necessary standard, while details live in secured systems.
When escalations touch electronic protected health information, your notification methods and tools should align with the administrative, physical, and technical safeguard expectations described under the HIPAA Security Rule. In practice, this pushes teams toward role-based access, controlled inboxes, and auditable records rather than ad hoc texting.
If you use an answering service, BPO, or contact center partner, validate how responsibilities are handled in a vendor relationship consistent with HHS guidance on HIPAA business associates, and reflect those boundaries inside the escalation matrix (what the answering team can see, do, and store).
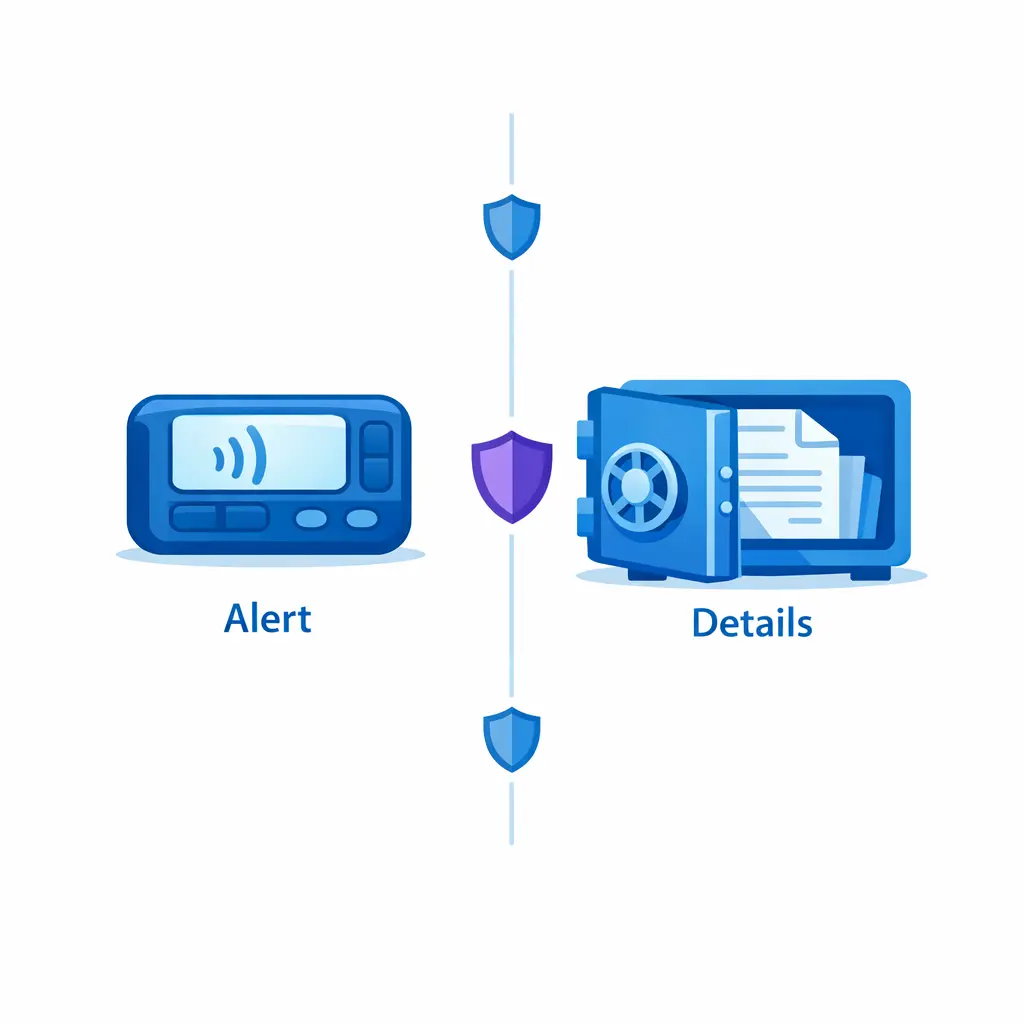
For legal intake, draw a clear boundary between brief alert messages and detailed privileged records. Brief pager prompts trigger the callback; full facts live inside the firm’s approved intake platform — not in the SMS thread.
For law firms and litigation support workflows, escalation content can include sensitive facts, identities, and strategic timelines. Structure your notification and storage rules to respect the duty of confidentiality described in ABA Model Rule 1.6 (Confidentiality of Information), including avoiding unnecessary detail in broad distribution channels. Operationally, this often means: brief pager/SMS prompts that only say “urgent intake, call back,” and full details captured inside the firm’s approved intake platform.
Tune the dial between noise and signal. Track false-positive escalations and missed escalations side by side; if either trends up, the triggers — not the agents — are usually wrong.
Broadcasting feels safe, but it creates diffusion of responsibility and notification fatigue. Use a primary-secondary-duty manager chain so that responsibility is explicit, and backups activate only when needed.
A caller can be calm during a critical situation, or angry about something routine. Anchor severity to time-criticality, risk, and required action. Train agents to document observable triggers, not feelings.
Close the loop: sample escalations weekly, feed findings into coaching themes and rubric updates, and update triggers when patterns repeat. A matrix without a QA loop rots in 90 days.
Unlimited warm transfer attempts destroy handle time and queue health. Put a timer in the SOP and define what happens next when the responder is unreachable.
“Create a ticket for everything” is how you get ticket chaos. Write explicit service desk escalation rules: what becomes an incident record, what stays as routine intake, and what gets summarized without opening a new work item.
Escalation matrices degrade when the business changes but the document does not. Put ownership on a process leader, schedule reviews, and treat exceptions as signals to improve the triggers or routing.
Escalation redesign fails when it is rolled out as a “big bang.” Pilot on a narrow set of S0/S1 triggers first, then expand. Your goal is reliability, not completeness.
Build a “rapid reclassify” rule into the SOP. If an event is misclassified, the responder can change severity with a recorded reason, and the team learns from it without blaming the agent.
Make escalation auditable: track volume by severity, acknowledgment-SLA pass rate, and outcomes. The same dashboard that satisfies an audit is the one that exposes drift before it becomes a problem.
If you want an escalation matrix that works under real call volume, it helps to validate it against live intake scenarios and staffing constraints. Go Answer supports overflow and after-hours intake with structured escalation workflows so urgent calls reach the right on-call roles without flooding your team with noise.
To discuss your call center escalation matrix, warm transfer procedures, and escalation SLAs, book a discovery call or request pricing. If you are still scoping options, you can also learn more about Go Answer’s intake coverage approach and map it to your internal escalation policy for contact centers.
Learn why thousands of companies rely on Go Answer.
Try us risk-free for 14 days!
Enjoy our risk-free trial for 14 days or 200 minutes, whichever comes first.
Have more questions? Call us at 888-462-6793
Learn why thousands of companies rely on Go Answer.
Have more questions? Call us at 888-462-6793
If you would like to get in contact with a Go Answer representative please give us a call, chat or email.

Thanks for your interest!
A representative will be reaching out to you shortly.
Have more questions? call us on 888-462-6793
